
The Browser DOM
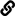
The DOM, as implemented in browsers, is a model to represent a HTML or XML document as a tree of nodes, and presents an API to access and manipulate these nodes.
There are twelve kinds of nodes, but two of them are used the most - element nodes and text nodes1. HTML tags are represented as element nodes, while the content inside these tags are represented as text nodes2.
In a typical browser environment, every node is represented as an object (with properties). The document object contains properties to access these DOM node objects.
The root node can be accessed with document.documentElement. Another example is the body, which can be accessed with document.body.
In the DOM API, elements which are not found, or referenced before they are rendered are null:
<!DOCTYPE html>
<html lang="en">
<head>
<script>
console.log(document.documentElement); // <html lang="en">...</html>
console.log(document.body); // null
</script>
</head>
<body>
<script>
console.log(document.body); // <body>...</body>
</script>
</body>
</html>
DOM Traversal
There are several ways to move around the DOM tree.
| Direction | Method |
|---|---|
| Up | parentNode |
| Down | childNodes, which includes all node types, and children, which includes only element nodes |
| Left/Right | previousSibling, nextSibling |
DOM Search
Aside from traversing, there are also methods to access nodes in the DOM tree directly. They are called on the document object, as in document.getElementById:
| Method | Description |
|---|---|
getElementById |
Find a node by its id |
getElementsByTagName |
Find all nodes with the given tagName |
getElementsByName |
Find all nodes with the matching name HTML attribute |
getElementsByClassName |
Find all nodes with the given class. Understands multiple classes |
querySelector, querySelectorAll |
Find the first node/all nodes that matches the given CSS3 query, respectively |
querySelector and querySelectorAll offer more powerful queries, but are less performant than the other methods.
All these methods that return multiple nodes in a HTMLCollection, except querySelectorAll, are live, meaning that they are automatically updated when the document is changed.
XPath
Another way to search through the DOM is using XPath.
DOM Node Attributes and Properties
Since DOM nodes are represented as objects, they have properties, just like JavaScript objects. These properties include implementations of the various standard DOM API interfaces, which are common across all nodes. Some properties are read-only, while others are modifiable.
Some important ones are listed below:
| Property | Description | Read-only |
|---|---|---|
nodeType |
ID of node type | Yes |
nodeName,tagName |
Name of element nodes | Yes |
innerHTML |
Contents of element nodes | No |
nodeValue |
Contents for other types of nodes except element nodes | No |
Additionally, each type of HTML DOM node has its own set of standard properties. MDN maintains a comprehensive reference of all these DOM object types, for example, the <form> DOM object.
HTML attributes of HTML DOM node objects can be accessed and modified with getAttribute and setAttribute, or with the properties of the DOM object itself:
e.getAttribute('id')
e.id
One should use the DOM object property most of the time:
In reality, there are only two cases where you need to use the attribute methods:
- A custom HTML attribute, because it is not synced to a DOM property.
- To access a built-in HTML attribute, which is not synced from the property, and you are sure you need the attribute (for example, the original value of an input element).
Attribute names and property names do not always have a one-to-one correspondence. For instance, e.class is forbidden because class is a reserved class in Javascript. Instead, its corresponding property name is className, as in e.className (this is highly relevant when writing JSX in React):
| Attribute name | Property name |
|---|---|
for |
htmlFor |
class |
className |
tabindex |
tabIndex |
Attribute and Property Synchronization
Most standard DOM properties are synchronized with their corresponding attribute (one notable exception is href).
I say most, because a select few standard properties are synchronized one-way only, for example the value property in the input DOM object. The property is synchronized from the attribute, but not the other way:
<!DOCTYPE html>
<html lang="en">
<input>
<script>
var input = document.getElementsByTagName("input")[0]
console.log(input.value); // ""
input.setAttribute("value", "I am number one!")
console.log(input.value); // "I am number one!"
input.value = "I am number two!"
console.log(input.getAttribute("input")); // "I am number one!"
</script>
</body>
</html>
Custom Attributes
HTML elements may contain custom attributes. These are not automatically represented by element properties, and so have to be accessed and modified with getAttribute and setAttribute. The HTML5 specification standardizes on prefixing data- for custom attributes.
DOM Modification
The most common methods of DOM node addition, removal, cloning and reinsertion are demonstrated below:
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body>
<script>
// Demonstration of node addition
var newNode = document.createElement('p')
document.body.appendChild(newNode)
console.log(document.body.children) // [script, p]
var anotherNewNode = document.createElement('div')
document.body.insertBefore(anotherNewNode, newNode)
console.log(document.body.children) // [script, div, p]
document.body.innerHTML += "<em><b></b></em>" // supports nested HTML tags as well
console.log(document.body.children) // [script, div, p, em]
console.log(document.body.lastChild.children) // [b]
// Demonstration of node cloning
document.body.appendChild(newNode.cloneNode(true)) // set to true to clone deeply
console.log(document.body.children) // [script, div, p, em, p]
// Demonstration of node removal and reinsertion
var oneMoreNode = document.createElement('input')
document.body.appendChild(oneMoreNode)
console.log(document.body.children) // [script, div, p, em, p, input]
var detachedNode = document.body.removeChild(oneMoreNode)
console.log(document.body.children) // [script, div, p, em, p]
document.body.appendChild(detachedNode)
console.log(document.body.children) // [script, div, p, em, p, input]
</script>
</body>
</html>